Re-designing a Leaky Microservice Integration
Embracing Behavioural Coupling

In a previous post, I discussed how I inherited a communication microservice that relied on Event-based integration and how that resulted in a leaky abstraction where the communication microservice has knowledge of all e-mail triggering events from all the microservices in our system.
I mentioned that a byproduct of this approach was bloated events that needed to contain enough information to compose those e-mails. But that was not all; these events also became the only way to get information from the producer to any of the many consumers, so they quickly started containing many fields aimed at specific consumers that are irrelevant to many others.
In one such case, there was a requirement change to set a priority as not all communications are created equal. The only way this would be possible whilst maintaining a perceived low coupling was to add a “Priority” field to all e-mail triggering events. However, “Priority” is meaningless to all but the communication microservice, and it indirectly creates a coupling that the original designers desperately wanted to avoid.
This “Priority” field is added by the producers of the events but controlled by the consumer. It is a simple boolean, but what happens if the communication microservice decides to change its priorities by making it an enumerator and adding a new priority level? Now all producers need to know about this change and update all their events from a boolean to a priority string.
This highlights a general drawback when Events are used to carry state. The producer owns the event, but the many consumers of that event influence its content. There’s an implicit coupling.
Coupling
I also explained in my previous post that what motivated this type of integration was to avoid Temporal and Behavioural coupling.
Firstly, this focus fails to acknowledge an essential concept in good microservices design: high cohesion. Things that change together should be grouped together.
Secondly, this interaction is intentional. The producers want to send an e-mail and know that there’s a microservice out there that does it. That’s why the events, in this case, are passive-aggressive commands, as explained in my previous post.
Use Commands Instead
We could embrace behavioural coupling in this case because we want to perform an action, but we are leveraging another microservice to perform it on our behalf. Hence, we should switch to using commands.
The communication microservice does not need to know about the numerous e-mail triggering events anymore; instead, it just processes one command — SendEmail. Microservices wanting to send e-mails can listen to internal domain events — if events are used within the boundaries of the microservice — and translate email-triggering events to the SendEmail command. This can be done in a gateway or an adapter.
When we want to change which events trigger e-mails, we only need to change one microservice. When we need to make communication-specific changes — only one microservice needs to change.
Synchronous vs Asynchronous Commands
Temporal coupling is something we can still avoid. Instead of issuing an HTTP/RPC synchronous communication, we should opt for asynchronous commands/messages. This way, the communication microservice does not have to be up when we want to send e-mails. Additionally, this allows the communication microservice to process messages at its own pace rather than being bombarded by numerous requests simultaneously.
When using synchronous communication, the flow is usually this: you call the microservice, it responds with an error, and you retry x number of times if not successful. Depending on the issue in the communication microservice, having all microservices hammering it in this way could exacerbate the problem. You can ease this by using exponential back-off strategies with jitters to randomize intervals and circuit breakers. However, you’ll need to add this functionality to every microservice and make it durable. This can be via a shared library or delegated to a side-car/service mesh.
But why add all this extra complexity to every microservice when you don’t need to? I believe you should strive to simplify your architecture when possible. The responsibility to get the e-mails out in a timely fashion lies with the communication service. Ergo, handling failures, keeping to SLAs, and all the ensuing intricacies should exist there.
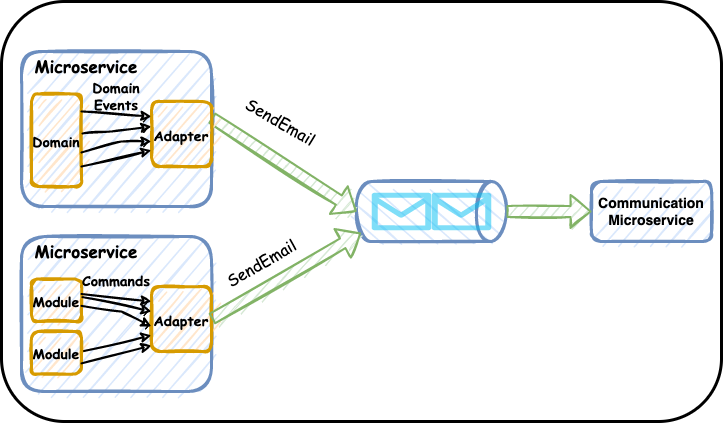
Asynchronous communication via queues gives us what we are after. If the messages are in a queue, the communication microservice can take its time to recover without disruptions to all other microservices. Retries, exponential back-offs, SLA calculations and all other complexities are kept within the confines of the microservice that actually needs it rather than spread across all microservices that depend on this communication microservice. Additionally, this approach gives you a durable store for messages, so there is no need to implement that yourself when adding a retry functionality. It will also simplify predicting the load on the communication microservice by allowing you to measure it by monitoring the queue depth and deciding how to best deal with that load to meet your SLAs.
In the next post, I will discuss how we implemented priority queues whilst maintaining low implementation coupling and encapsulation.