Lessons from the Trenches: CQRS, Event Sourcing, and the Cost of Tooling Constraints

Several years ago, I led the implementation of a set of CQRS-based, event-sourced microservices built using Domain-Driven Design (DDD) for a bank. From the outside, this might sound like a CV-driven mix of patterns and technologies, but each decision was deliberate, chosen to serve a highly complex banking domain and driven by business needs. In regulated industries like banking, these choices are often constrained by strict technology policies, and this was no exception. Our tools were limited to SQL Server and IBM WebSphereMQ—neither built with event sourcing in mind.
This post will shed light on the implementation within the service boundary. The events required to hydrate aggregates are private events and are only consumed by internal components. External integrations are done via summary events or commands, depending on the integration requirements.
Event Sourcing and CQRS do not have to be used together; you can implement each on its own. They are particularly powerful when used in tandem, which is why we chose that route. Event Sourcing and CQRS also do not have to be implemented with DDD. DDD is suitable for complex domains, so use it only if the problem domain warrants it. DDD with Event Sourcing and CQRS offers numerous advantages, which I will cover in future posts.
Note: Projections = Read Models. I use the two terms interchangeably in this post.
Why CQRS and Event Sourcing Were the Right Fit
Banking requires precision, transparency, and the ability to fully understand the journey of every piece of data. Event sourcing and CQRS weren’t chosen just for traceability—they were selected for their ability to model change over time, unlock replayability, and enable rich domain behaviour:
- Event Sourcing as a Source of Truth: We captured every state change as an immutable event, not just for audit trails but to act as the backbone of our domain. By persisting events as the single source of truth, we could rebuild any projection at any point, experiment with new features without rewriting history, drive compensating workflows, and model the temporal nature of business processes. This approach also enabled debugging and analysis capabilities, allowing for the replay of entire histories to understand behaviour, identify root causes, and test future scenarios safely. The most significant benefit of EventSourcing is that business information is not lost. This proved valuable time and time again when business rules changed, and it required retrospective application, or a piece of data we didn't care about suddenly became important due to market changes or new regulatory rules.
- CQRS for Simplicity and Focus: By separating reads from writes, we created two distinct models optimised for their respective concerns. The write side was tightly coupled to rich domain logic, enabling us to enforce invariants and express complex behaviours, while the read side was tailored for fast queries, analytics, and reporting. Crucially, this separation let us:
- Optimise independently: Different SLAs, data stores, models and scaling strategies for each side (e.g., transactional stores and strict consistency on the command side; denormalised, query‑friendly views on the read side).
- Move faster with fewer collisions: Read‑model teams could add new projections, reshape views, or precompute aggregates without touching command code or risking domain integrity.
- Enable safe evolution: We could rebuild or backfill read models from event streams, run blue/green releases of projections, and A/B test new views with zero impact on command handling.
- Simplify reporting and analytics: Read models expose denormalised, purpose‑built views to BI/MI without leaking domain complexity or compromising transactional workloads.
- Align responsibilities: Command handlers focused on correctness and invariants; materialisers/subscribers focused on latency, caching, and query performance.
- DDD for Managing Complexity: Domain-Driven Design provided a framework for modelling a complex financial domain with precision. By defining explicit bounded contexts, we maintained clarity in the ubiquitous language, removed the need for translation between business and implementation, ensured teams owned their models independently, and avoided coupling that leads to tangled big-ball-of-mud architectures. Each bounded context became a clear boundary for change, allowing teams to evolve their models without breaking others and making the architecture easier to reason about over time. This also helped in managing complexity and keeping teams' cognitive load in check.
We had the right architectural patterns to solve a complex banking domain, but the tooling available limited how cleanly we could deliver on that vision.
The Challenges of SQL Server and WebSphereMQ
With no purpose-built event store or streaming technology available, we had to implement a lot of plumbing to make our vision work:
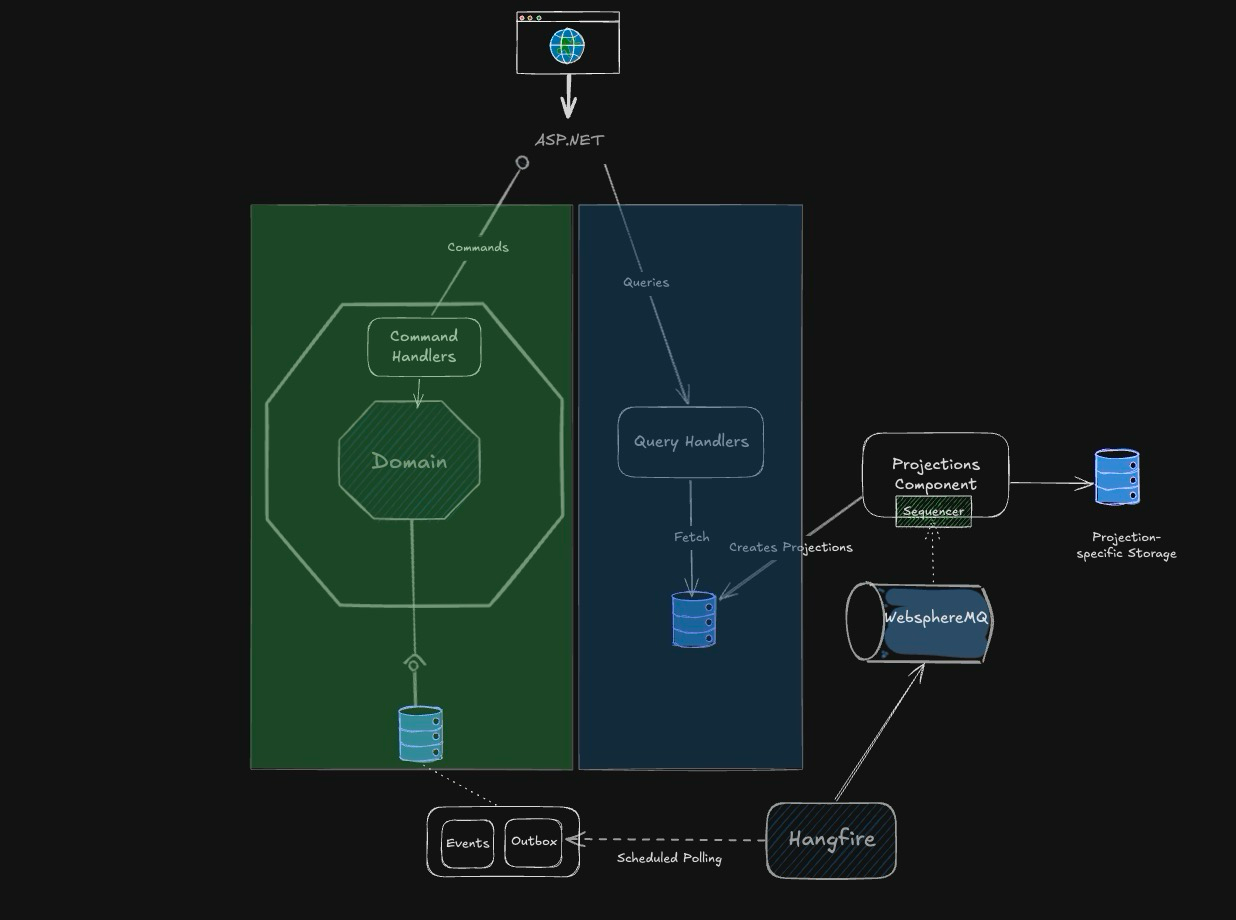
- The Outbox Pattern: To guarantee reliable storage and publication, we implemented the Outbox pattern in SQL Server: commands appended domain events into an
Outboxtable in the same transaction that stored the aggregate state as an event stream. A Hangfire-driven publisher polled the outbox and pushed the events to IBM WebSphereMQ. We added idempotency and ordering safeguards (dedupe keys, per‑aggregate sequence numbers,PublishedAt/Attemptscolumns, exponential backoff, and dead‑letter handling) to cope with retries and at‑least‑once delivery. - Background Processing with Hangfire: We introduced Hangfire as a resilient, scheduled publisher for the outbox. This turned Hangfire into a reliable bridge between transactional writes and asynchronous publication, at the expense of more moving parts to configure, monitor, and scale. However, although Hangfire takes some of the heavy lifting, there is a lot more complexity required to use it as part of an outbox.
- Queues & Workers: Separate
high,default, andlowqueues; dedicated workers for the outbox publisher to avoid starvation from other jobs. Horizontal scale gave us linear throughput. - Batching & Flow Control: Read the outbox in batches (e.g., 200–500 rows), publish to MQ with backpressure (windowed concurrency), and commit checkpoints only when a batch completes successfully.
- Retries & Backoff: Immediate retries for transient MQ faults, then exponential backoff with jitter. Max attempts promoted a message to a DLQ record for human review.
- Idempotency: Message keys derived from
AggregateId + Versionensure at‑least‑once delivery don’t duplicate side‑effects downstream. - Operational Safety: Graceful shutdown drained in‑flight batches; circuit breakers paused publishing on systemic MQ faults.
- Queues & Workers: Separate
- Projection Components:
The infrastructure and code that materialise read models from event streams, responsible for transforming ordered domain events into query‑optimised views.- Projections Handlers: These house projection-specific event handlers and are responsible for projection-level concerns such as: projection versioning (v1→v2) with side‑by‑side build and blue/green cutover to avoid downtime. They also maintain projection schemas and indices, and keep schemas purpose‑built and independent of event payloads.
- Event Handlers Per Projection: Translate events into view updates (insert/upsert/delete), enrich with reference data where needed, maintain
LastAppliedVersionper stream, and ensure idempotency (ordering will be handled by the Sequencer). - Storage: Each projection use case (reports, UI screens, searches, dashboards, etc.) has a read model shaped specifically for it. These are stored as denormalised tables in SQL Server. If there are no tool restrictions, you can select the right store for each use case (e.g., document/kv for flexible queries, search indices for text analytics).
- Rebuild & Replay Components: Support full replays and incremental backfills from checkpoints; shadow projections for validation before cutover; online reindexing where supported.
- Projection-specific Storage: Because our events were intentionally focused (avoiding coupling event payloads to every query need), read models often required data from previous events. Hence, we required access to the event stream, but since we were forced to use an AMQP-based technology, that was not possible. To address this, we built private, supporting projections to serve the projections powering UI screens and reporting. The approach worked well, but it carried operational costs and accidental complexity solely to bridge the inadequate tooling gap.
- Sequencer: MQ gave us at‑least‑once delivery but not per‑stream ordering. At the time, functionality like, for example, Azure Service Bus Sessions that guarantee ordering were not available, which is fine when delivering discrete messages, but not when creating read models, where not getting the order right will result in incorrect information. Hence, we enforced order and correctness in our projections' building subscribers:
- Per‑Aggregate Ordering: Each event carried a monotonic
Version. Projections persistedLastAppliedVersion; ifVersion > LastAppliedVersion + 1, the event was buffered briefly while waiting for the missing gap. - Gaps & Timeout Policy: After a configurable timeout, we trigger a targeted catch-up (re-fetch from the outbox/primary store) to fill gaps caused by network reordering.
- Deduplication: A
(StreamId, Version)uniqueness constraint prevented double‑apply on retries. - Out‑of‑Order Buffer: A small, bounded priority queue maintained order per stream.
- Metrics: We tracked reorder lag, buffer depth, and gap timeout rate per stream to detect systemic issues early.
- Per‑Aggregate Ordering: Each event carried a monotonic
Order Enforcement — why an out‑of‑order buffer?
MQ provides at‑least‑once delivery but not per‑stream order. The buffer is a small, bounded priority queue per stream that holds versions that arrive ahead of their turn. It lets you wait for the missing gaps, then apply events in strict order.
How it works: (1) Ifv == last+1apply and drain; (2) Ifv > last+1buffer and start a gap timer; (3) On timeout, attempt catch‑up; if still missing, pause that stream and alert; (4) Duplicates (v <= last) are ignored.
Why it matters: preserves correctness without stalling other streams; only the problematic stream is paused.
These mechanisms preserved correctness, but they are precisely the sort of plumbing a purpose‑built event store (with ordered streams) gives you for free. The system worked, but complexity grew quickly. What started as an elegant architecture became a heavy burden.
What EventStore Could Have Given Us
We trialled EventStore at the time and were struck by how much accidental complexity it could have eliminated. Here’s what we saw:
- Atomic Storage and Publishing: Events can be persisted and published in a single transaction, as the EventStore serves as both storage and publisher, eliminating the need for the outbox pattern and the Hangfire service entirely.
- Built-in Projections: EventStore’s native projection support would have saved us from building and maintaining custom projection code.
- Cacheable Streams: With streams easily accessible and cacheable, we wouldn’t need additional read model-specific stores to serve extra or historical data.
- Guaranteed Ordering: Streams are ordered, removing all the complexity of implementing components that sequence messages.
Yes, EventStore had a learning curve, but it was purpose-built for this exact problem. Had we been allowed to use it from day one, we would have spent far less time building infrastructure and far more time solving business problems.
It would have meant we could remove the following:
- The Transactional Outbox as it is no longer needed because the Event Store database persists and publishes events atomically.
- Hangfire is also no longer required, as it was only used to implement the Outbox pattern.
- The Sequencer and all the complexity associated with it, as the Event Store exposes an ordered event stream.
- Projection-specific Storage since the events are immutable, the event stream is infinetly cachable resulting in the removal of the Projection-specific Storage component as we can cheaply retrieve the historical data we requires directly from the event stream.
- WebsphereMQ as the Event Store does the publishing.
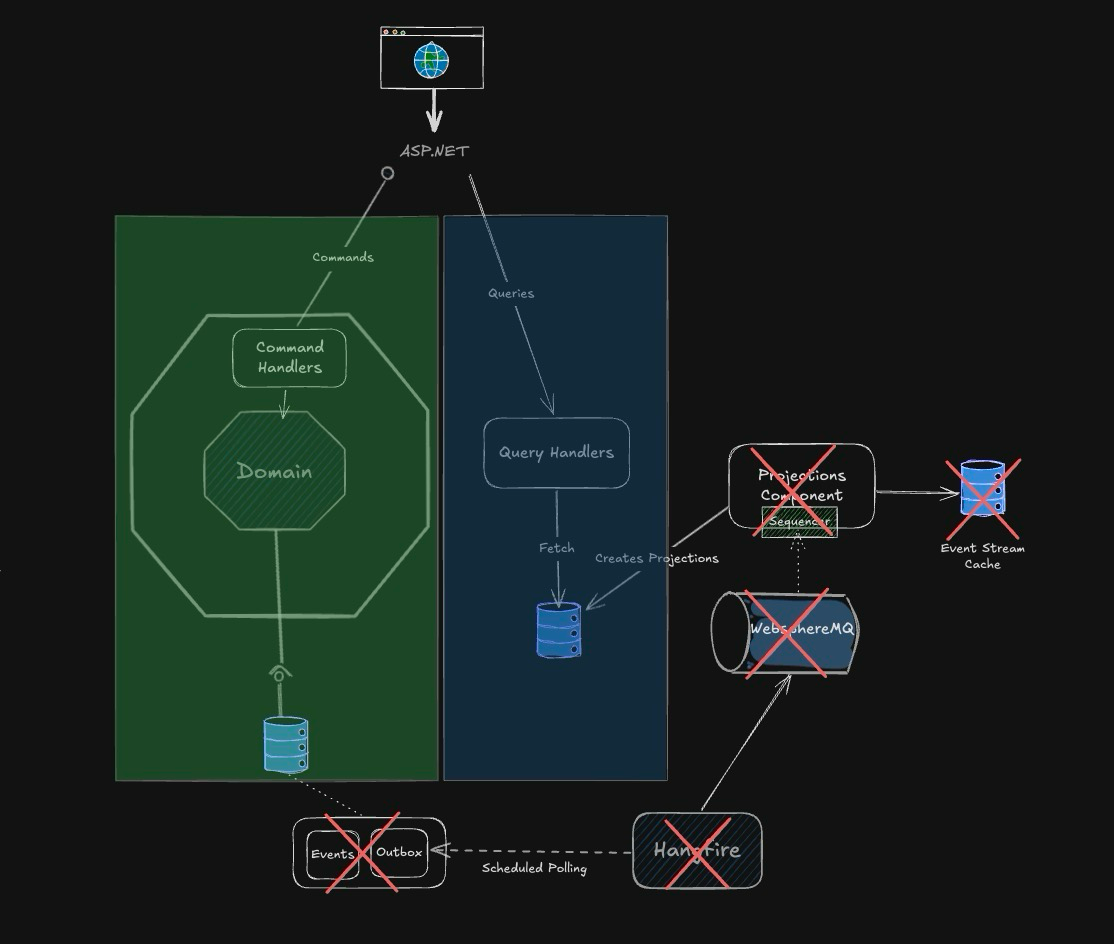
The overall architecture is simpler with a lot fewer moving parts and the EventStore doing a big portion of the heavy lifting so we can focus on the things that move the needle.
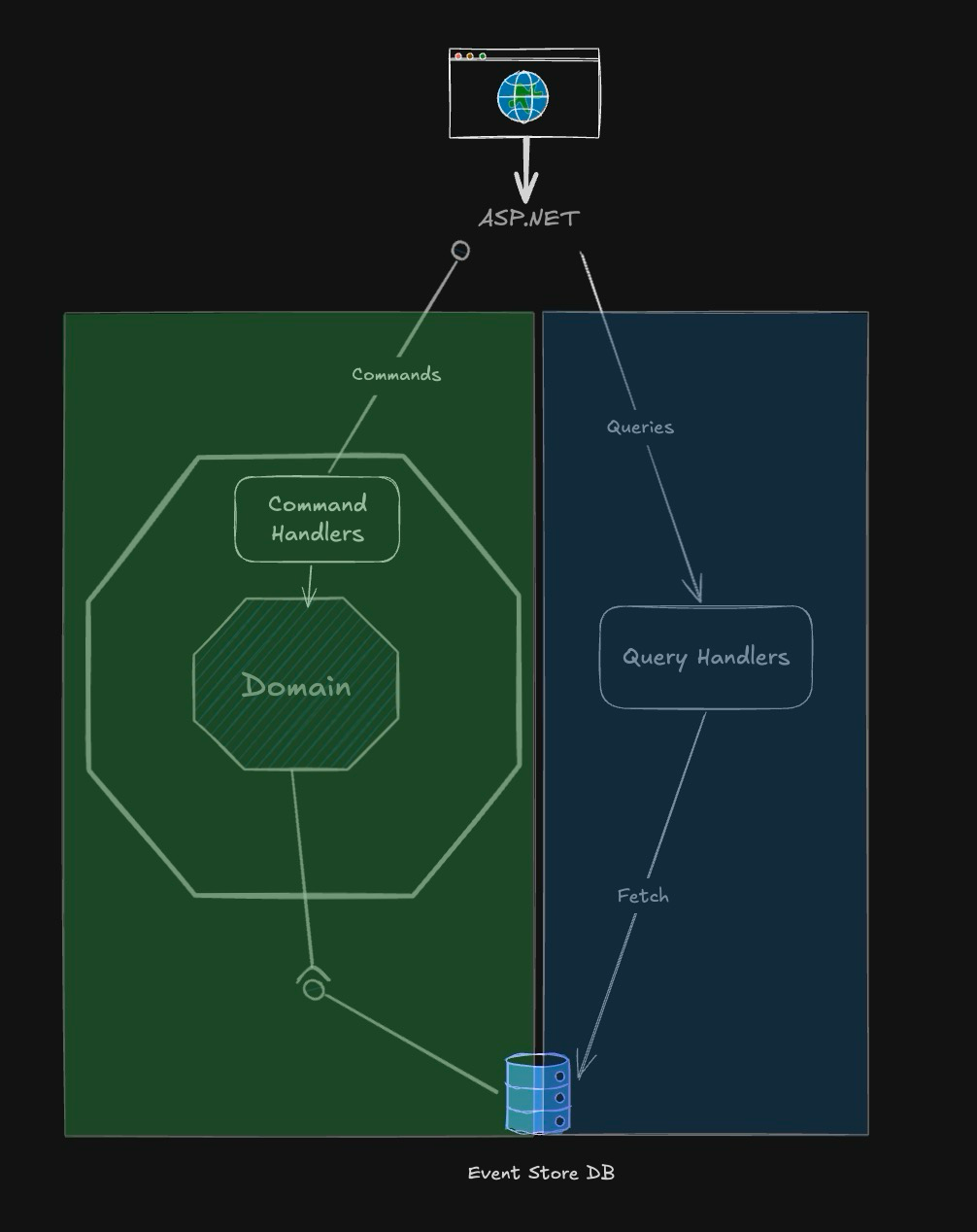
Of course, some of the complexity is shifted to EventStoreDB, but this is the complexity it was designed to handle. This alignment means we are using battle-hardened components constructed specifically to solve these problems by teams that have dedicated time and resources to not only understand the challenges but test and validate them in a range of setups and configurations over a larger time period.
When Simplicity Becomes Complex
Enterprises often limit the number of tools in their stack to simplify operations and reduce risk. This is understandable. But sometimes, these guardrails shift complexity elsewhere. In our case, constraints on tooling forced us to rebuild functionality that already existed in EventStore.
The lesson? Tool consolidation does not mean less complexity.
- Limiting tools can reduce operational load, but they also risk increasing development complexity.
- Exceptions should be made for tools that dramatically simplify core architectural patterns.
- Simplicity is achieved when the right tool fits the right problem, not just when there are fewer tools.