Evaluating an Asynchronous Processing Design
I was recently asked to provide feedback on an implementation designed to decouple accepting requests in a service from processing them. Initially, I intended to provide direct feedback, but I realized this would be an excellent topic for a blog post.
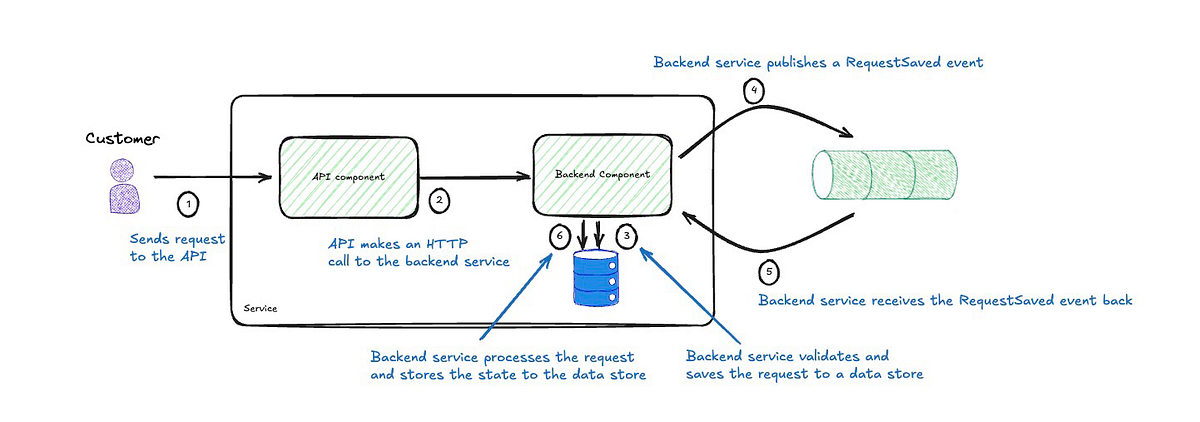
Overview
The diagram above illustrates a cut-down version of the proposed high-level design and describes the steps involved. This was presented as a pattern to adopt when processing requests asynchronously.
I have sometimes been guilty of skipping over the thought process when blogging, so I will think out loud in this blog post. I will explore dead-ends and explain why I’m discarding them before ending with how I’d solve this. Spoiler alert: I don’t think using events is appropriate in this case, but bear with me as I take you through why I think that is.
The proposed implementation overlooks some failure scenarios. For example, after storing the state in a database, an event is published to a message queue. If either action fails, the exception is propagated to the customer for a retry. However, if storing the state succeeds but event publishing fails, retrying may create a duplicate state unless the process is idempotent. While storage is cheap, ensuring idempotency is crucial if duplicate records could lead to an invalid service state.
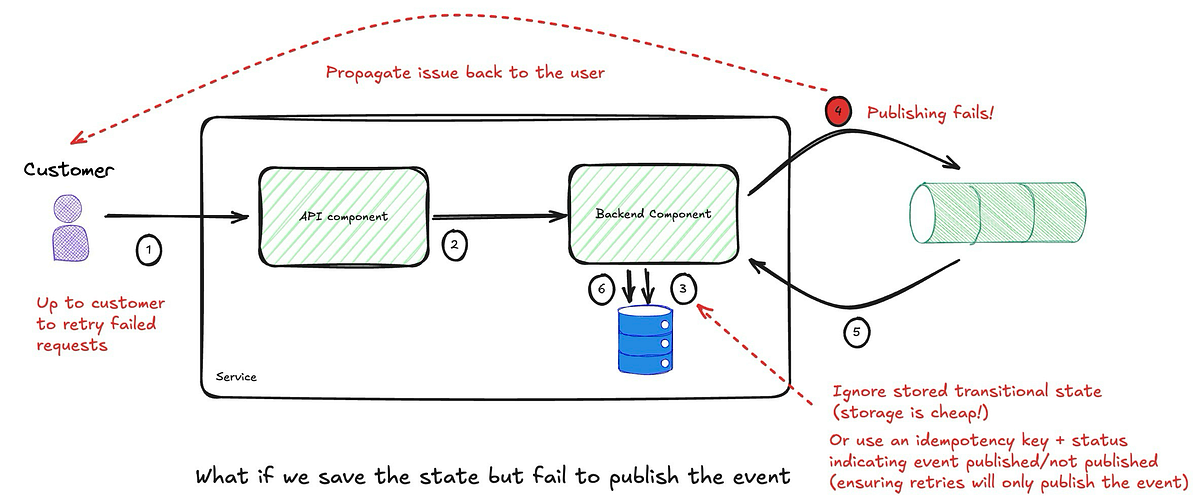
What about Atomicity?
But does this solve the issue? Should these two actions be atomic? Let’s unpack that a little more.
The document accompanying this implementation indicates that the state being saved here is just to acknowledge that the request was received. This alters how I approach this, but before I explore that, let’s tackle the case where it is part of the business process and, therefore, affects the validity of the internal state.
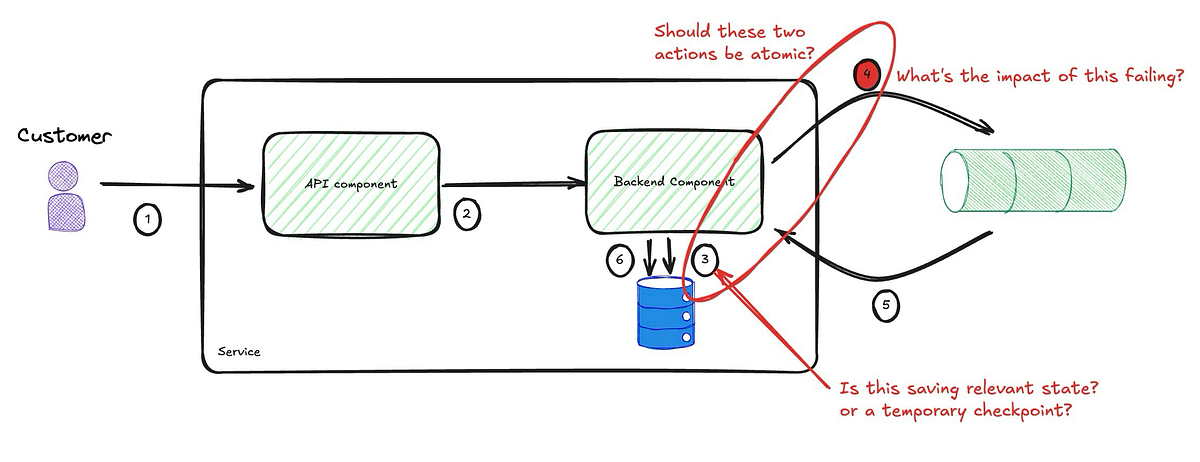
The service should never be allowed to get into an invalid state, and it’s the service’s responsibility to ensure this. Hence, the two actions must be atomic. We cannot rely on external actors to maintain the validity of our internal state. In other words, we can’t depend on the customer to retry until the operation succeeds. The service must be resposnsible for maintaining its integrity.
So, how do we ensure atomicity? Since these two actions utilise different technologies, a distributed transaction is required. Distributed transactions have numerous drawbacks and should be avoided. They are not supported in the cloud, where most systems run nowadays, and, as I have blogged about in the past, they, among other things, reduce your technology choices and lock you in. One way to circumvent the need to use distributed transactions is through implementing the transactional outbox pattern.
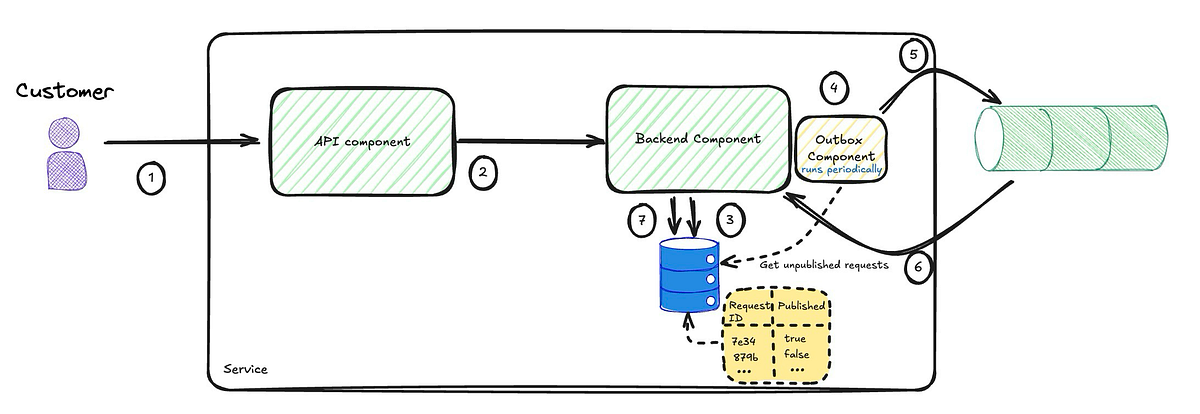
Note: Another way to implement this is through a Change Data Capture. I will blog about this in the future and compare and contrast it to the outbox pattern.
This will benefit the backend component in two ways: the actions will either succeed or fail together, and we will reduce the types of failures that directly affect customers to one.
Reduced Customer-Facing Failures: Failures that directly affect customers are reduced to one—failing to persist the event—since the outbox component can retry the background publishing process without directly impacting the customer experience.
Atomicity: The actions either succeed or fail together, ensuring the service remains in a valid state.
Temporary State Scenario
Back to the scenario where the state we are saving is merely used as a checkpoint and a temporary placeholder to store the request's data. Then, we can simplify the implementation by not storing this temporary state in the database. Instead, we include it in the message and subscribe to it.
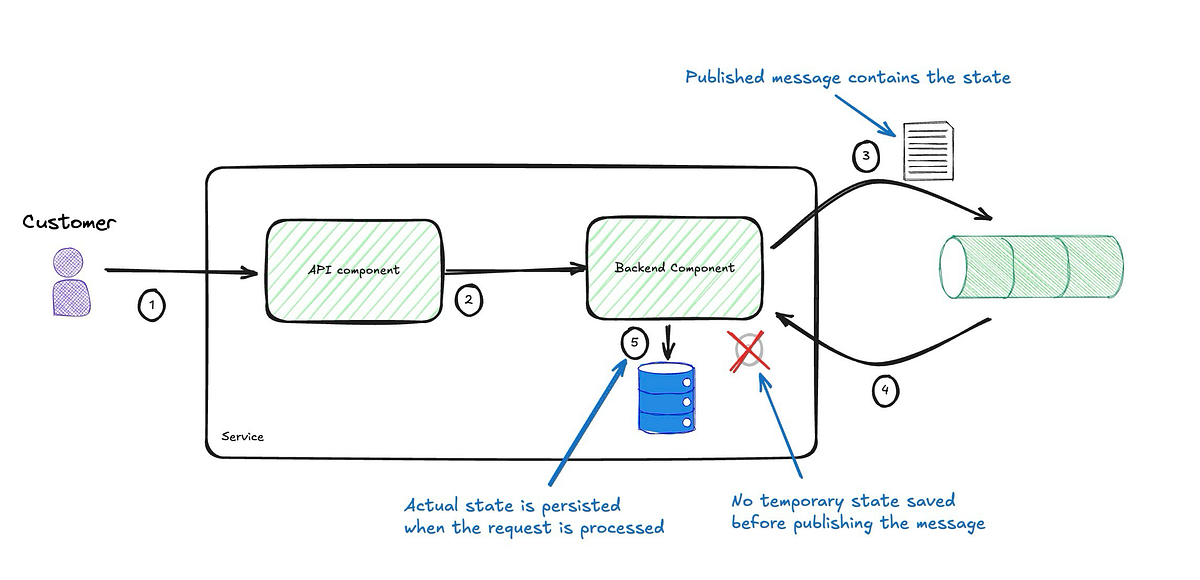
The revised diagram above shows a more straightforward process without needing a transitional state. The event now contains the request payload, and publishing it triggers processing, so we only need to store the end state once processing is complete. How does this compare to the original solution?
- Reduced Customer-Facing Failures: Failures that directly affect customers are minimized, as there’s no need to persist the event.
- No Temporary State to Maintain: No need to worry about orphaned records or cleanup since the validity of the service’s state isn’t affected.
This approach also has downsides: the event payload is strongly coupled to the request payload. However, since the event is private and intended only for the backend component publishing it, and both the API and backend live within the same service, the impact of this coupling is close to zero.
Disintegration Drivers
The reasoning behind separating the API and backend components in this pattern is unclear. Providing guidance on when to integrate or disintegrate components would be helpful, as patterns are often adopted without much thought. I’ll explore these drivers further in a future post.
Temporal Coupling
One last thing I should point out before I start critiquing the use of events is the temporal coupling between the API and the backend component. This is tempered by the fact that the two components exist within the same service, but nevertheless, this coupling means they both have to be up and running every time a call is made.
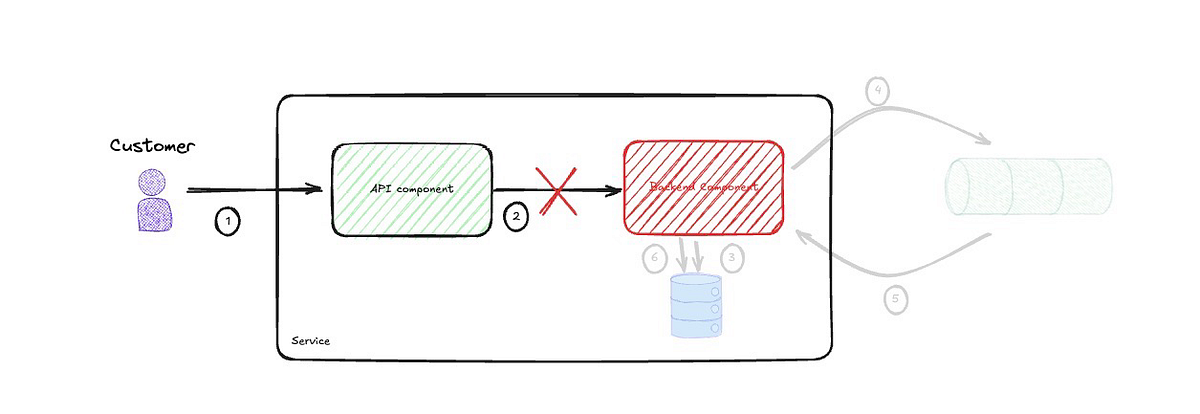
I am not advocating for every integration to be asynchronous. Such absolute statements should not exist in architecture, as every decision is a trade-off and unique to your context and drivers, business and technical. I will delve into this in more detail in a future post.
At-Least Once Delivery
Messages received from the queue are guaranteed to be delivered at least once, so idempotency must be implemented in the backend component to prevent undesired side effects from message redelivery.
Finally…
Is this the final solution? Does this solve everything? Well, like I said at the top of this blog post, I wouldn’t design this using events. Let me explain why.
Why This Design Misuses Events
- Ignoring Intentionality: The events produced in this implementation are effectively commands disguised as events (or passive-aggressive events). They’re intended to instruct the service to process requests; explicit commands should be used in such cases.
- Expecting an Action: Events represent one-way communication—they signify that the publisher's job is done, and whatever happens as a result is inconsequential. This doesn’t fit the purpose of the events used here, which are intended to trigger request processing.
- Event Integrity: Events represent facts and cannot be rejected. However, here, we are using an event as an instruction to process a request included in the event's payload. Therefore, if the request violates business rules, we need to reject it, which contradicts the concept of an event as an indisputable fact.
- Using Technical Events: Events should represent business-relevant facts and be modelled accordingly. The intermediary state, say 'RequestReceived', is an implementation detail. Such events are acceptable only if they simplify the design and remain private, but that doesn't seem to be the case here.
If it looks, walks and quacks like a duck…
The design is trying really hard to stick to using events, but those events have all the attributes of commands. Actually, they are commands in every sense but name. They hint very hard at the service to do something and expect it to oblige just in a roundabout way.
So, we can replace the event being omitted with a command to process the request (ProcessRequest) sent by the API to the backend component.
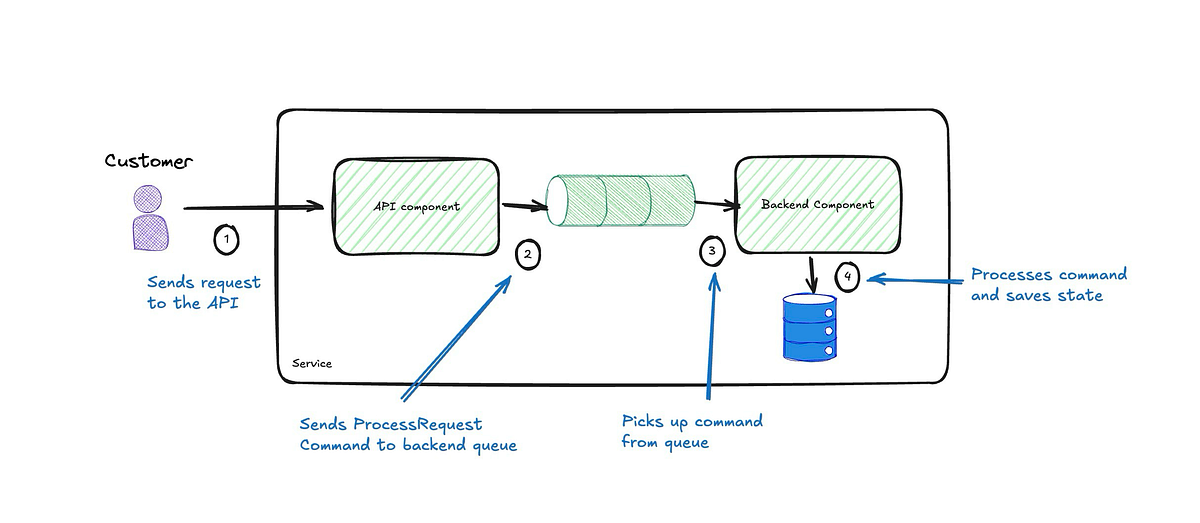
The overall process is now more streamlined, removing temporal coupling between components, which enhances resiliency by allowing them to operate independently. Temporal decoupling means the components do not have to be simultaneously available, improving the system's robustness to partial failures or downtime. The backend component is also simplified by eliminating the need for event publishing and subscribing, ensuring it receives clear, direct instructions to perform actions rather than ambiguous signals. This direct communication reduces unintended side effects and avoids accidental complexity from other components misinterpreting the events. By replacing events with explicit commands, the design also clarifies each action's intent, leading to a more understandable and maintainable codebase.
Furthermore, this approach improves fault isolation, as components can fail independently without cascading issues across the system. It also simplifies troubleshooting and debugging, as the actions are well-defined and traceable. Defining the backend's responsibilities explicitly promotes a clear separation of concerns, which is crucial for scalability and extensibility. These changes lead to a more resilient, maintainable, and robust system architecture that is easier to evolve and adapt over time.
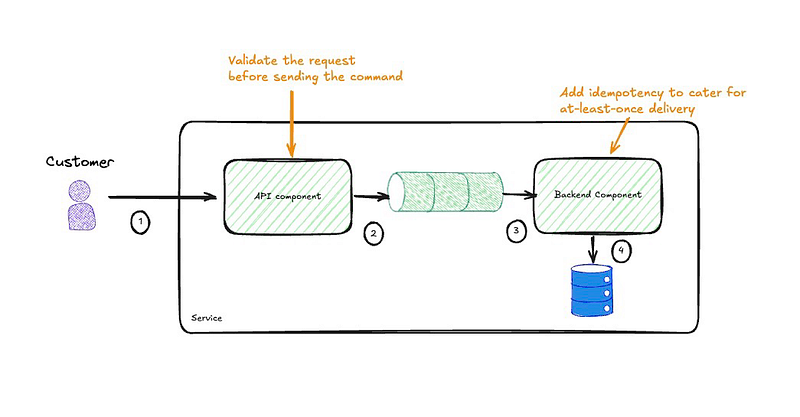
One last thing to consider: validation must move to the API component, but this is just high-level validation to ensure nothing glaringly obvious that would result in the request failing when processed later. Also, we’ll need to retain the idempotency features of the backend component to handle re-delivered or retried messages.