Event Sourcing — Oops, wrong Aggregate Boundary
How I shared streams to split an aggregate and why.

How I shared streams to split an aggregate and why.
With most DDD projects, you try to understand the problem domain as best as possible before modelling the solution domain and starting the implementation. Now, in an ideal world, you’d be given access to domain experts and allowed time to extract and document as much knowledge as you can from them to aid in the modelling process. Maybe even run a few “Event Storming” sessions. However, you’re not afforded that luxury more often than not, and you start your modelling at the point of least knowledge.
Beginning with an imperfect model is not a problem, as there’s no such thing as a perfect model. Eric Evans has a great talk about a good design being imperfect. Hence, remodelling a domain is not uncommon; rather, it is expected.
This process becomes even more complicated when you add Event Sourcing into the mix. That is because you now move into the realms of append-only models. In a future post, I will discuss what this means when it comes to versioning your events, but here I want to specifically discuss a problem I faced with event-sourced aggregates and how I chose to address it.
Wrong aggregate boundary
As requirements evolved, the system grew drastically different from what I expected and, thus, from how I modelled the problem domain. It became clear that the aggregate was doing too much, and I would need to split it.

The aggregate boundary is wrong! Now what?
The course of action from here on depends on how the boundary is wrong. Either the aggregate should be split or combined with another one. That could be the result of myriad reasons. Maybe the aggregate was doing too much, and there was a second aggregate in there waiting to emerge. Or, possibly — to enforce the current business rules — one should expand the aggregate to contain another one. I will cover how to tackle these issues in a future post. In this post, I will delve deeper into my problem: splitting the aggregate.
Splitting an event-sourced aggregate
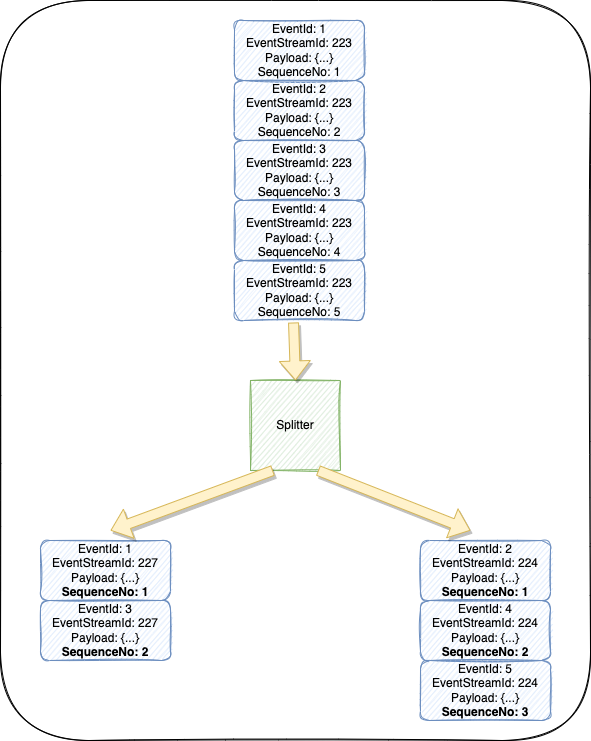
Event-sourced aggregates are built on top of a stream of events. So when you want to split the aggregates, most, if not all, of those events in the event stream will only be relevant to one of the aggregates.
Sharing an event stream
The pragmatic and most straightforward way of going about addressing this issue is to share the event stream. I had a lot of pushback when proposing this; the consensus was that it’s a quick fix and not the proper way to tackle this issue. However, there is nothing wrong with sharing the event stream, it is a practical solution that lets you quickly get on with the important stuff, and that is providing value to the business.
This approach is:
- Easier to do in a live system
- Does not require transforming the event stream
It is especially easier when compared to alternatives, in this case: splitting the event stream, which requires splitting both the code and the persisted event stream. Splitting aggregates in code is what we actually want to do, so that’s OK. However, going through the entire event stream and altering the events on a live system is better avoided.
There are numerous challenges when it comes to doing this in a live system, but that’s a topic for another post. The one thing I want to point out here is that you’d need to ensure that the application can handle both event stream configurations to allow for a seamless transition.
Split at The Application Level
When sharing the event stream, the split actually happens in code at the application level. Hence, each aggregate will replay all events in the stream when hydrated but only apply ones pertinent to it. This would make it easier in the future if you ever want, or need, to split streams.
As far as the code goes, the two aggregates will be completely separate. However, the ones that were created before the split will share the same aggregate ID. This should have no bearing on the domain as the aggregate ID is irrelevant to the domain logic; In fact, the aggregate ID can be removed from the aggregate code entirely.
An aggregate ID is usually used for two purposes:
- loading the correct event stream: this actually happens in the aggregate repository, which is part of the infrastructure code rather than the domain.
- correlating events for projections — all events usually have an associated aggregate ID because they are usually needed to build up a representation of an entity in the read models.
Both of those cases can be handled without including the aggregate ID in the aggregate itself.
In my experience, when splitting aggregates and sharing a stream, there is not a lot of contention between the two aggregates. This is usually because the two have dissimilar lifecycles and loads that do not overlap very often. If that does not prove to be the case and you end up with numerous optimistic concurrency issues, it may be a sign that sharing the stream is not the best solution — you might need to look into splitting the streams themselves.