Avoiding Distributed Transactions — Outbox Pattern
I’m currently architecting a payment system for domestic payments for a UK bank. This is a greenfield system that is going to consist of a…
I’m currently architecting a payment system for domestic payments for a UK bank. This is a greenfield system that is going to consist of a few microservices. The core domain will be using Event Sourcing and DDD. Event Sourcing helps us meet some of our regulatory requirements, and DDD bridges the gap between us and the business by providing a ubiquitous language for this complex domain.
The interactions between the different microservice within the payments bounded context is choreographed to reduce coupling. I have blogged about choreography here.
Domain events produced by the core domain are published internally, and some are transformed into summary events published on a public topic. I will discuss the rationale behind not publishing domain events externally in a future post.
I have discussed the technology constraints enforced by distributed transactions and briefly touched on its limitations in a previous post. So, I’m going to skip the why in this post and delve into the problem we are trying to solve. We needed to persist the domain events in the event store and publish them. These two actions must either both succeed or get rolled back. They must be atomic.
Most event sourcing dedicated databases solve this by being both the persister and the publisher. Unfortunately, we could not use an event store database as we were restricted to only choosing from the products already used in the organisation. In our case, those were SQL Server and Websphere MQ.
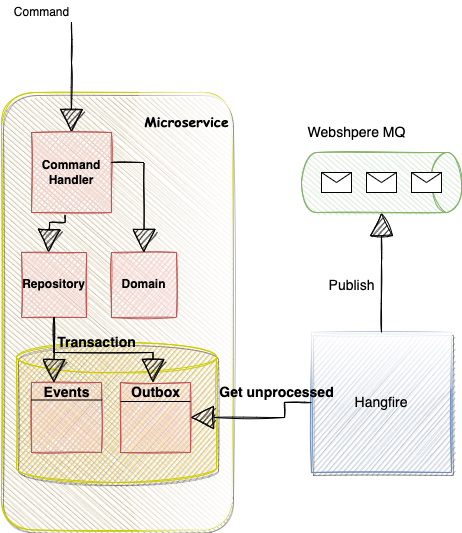
Atomically persist and publish events
There are a couple of ways I can think of to avoid distributed transactions:
- Breaking the transaction into separate microtransactions with compensating actions
- Restricting the transaction to a single technology
Microtransactions with compensating actions
Can we create two separate transactions that are reversible in case of failure? Publishing to a topic is not easily reversible. But writing the event to the database is. When using this technique, you order the microtransactions based on the likelihood of failure and ease of compensation. So, in this case, the process would start with writing the event to the database and then publishing to a topic. If writing to the database fails, the transaction rolls back, and the process is abandoned. If publishing to the topic fails, the first step to persist the event is reversed by deleting the event from the database. Though this could work in theory, it poses a few problems in practice. What happens if, in that time, another action is performed against the aggregate? Can we then ensure the aggregate is still in a valid state after the event is deleted? What if we also want to publish the event in-memory as other aggregates within the domain may need to act on it? How can this be reversed? What if more than one aggregate reacted to this event — how can we undo all their actions too?
This solution starts to unravel very quickly.
Restricting the transaction to a single technology
The premise here is that you’ll never need a distributed transaction if the action to be performed involves a single technology. And this is where the outbox pattern comes into play. We can write the event to the event store tables in the database as well as add a record to another table (outbox) — to indicate that this event should be published — in one atomic transaction. Another process then monitors that outbox table periodically, publishes all unpublished events and marks them as so.
How do we monitor the outbox and publish events? And what happens when publishing fails? Hangfire and idempotency were our saviours here. All downstream systems are built with idempotency in mind from the start, so failures can be retried with no side effects. Hangfire handles the rest as it provides recurring jobs out-of-the-box.
The recurring job runs periodically, grabs all outstanding outbox messages, and then enqueues them individually as Hangfire jobs. Enqueued jobs are automatically retried on failures.
The enqueued job calls a mediator to publish the event, and a handler listens to those events and puts them on the Websphere MQ topic. Using a mediator (MediatR) provides a pipeline that is easily extendable. This is how we handle inter-aggregate communication; another handler is added to use an in-memory domain event publisher that other aggregates within the domain subscribe to. In DDD, commands should not require updating more than one aggregate in a single transaction- if they do, then your aggregate boundaries are wrong — however, when a command requires business rules on other aggregates to be executed, we should use eventual consistency. And this implementation allows for that. The same rules applied to external event consumers apply to internal ones: they must be idempotent, thus allowing us to retry sending the messages to other aggregates until they succeed.