Sagas — Part 4: Design Considerations Continued
Exceptions, Cancellation, Idempotency and Isolation
This is a continuation of the last post in this series about design considerations in Sagas.
Other posts in this series:
Sagas — Part 1: An Introduction
Sagas — Part 2: Sagas in Distributed System
Sagas — Part 2b: Sagas in Distributed Systems Continued
Sagas — Part 3: Choreography Instead?
Sagas — Part 4: Design Considerations
Cancellations
When cancelling a saga, all already completed steps should be rolled back, and that could be expensive. Additionally, as discussed previously, these techniques could be used to avoid overlapping Sagas.
There are several ways to limit the impact of cancellation, depending on what makes sense in your business:
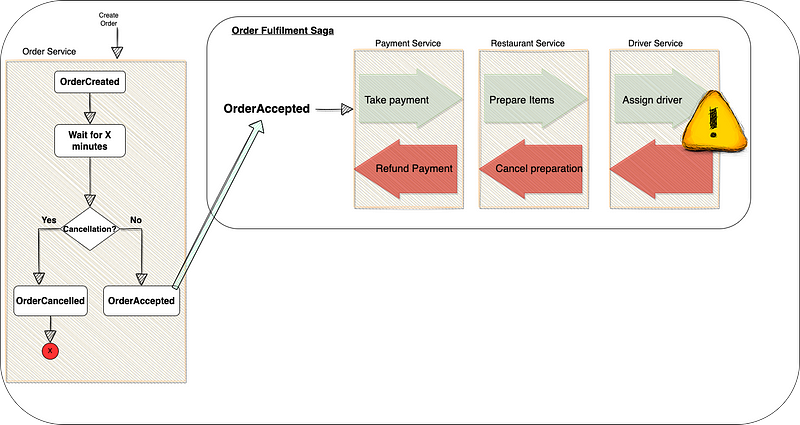
- Allow Saga cancellation in the early steps only: determine a point after which cancellation is not allowed and strive to set that point as early as possible in a saga. Suppose the Deliveroo Saga from the previous post (or the below diagram on the right-hand side) had a lot more steps; you could pick the “Item preparation” step as the last allowed cancellation point. This is the earliest logical point to cancel an order, as once the restaurant starts preparing the items, cancellations become really expensive.
- Buyer’s remorse: wait for a pre-determined grace period before triggering the Saga. Once that time has elapsed, the process can longer be cancelled, and the Saga is expected to be run to completion. Applied to the Deliveroo Saga, a delayed trigger can be used to check in X minutes if the Saga has been cancelled and, if not, start a non-cancellable Saga. Otherwise, don’t start the Saga at all. This way, we avoid any associated costs with cancellations.
There could also be instances where it makes business sense to allow cancellation at any time. Or cancellation is allowed within X minutes, but the Saga still starts immediately (no grace period). The cancellation costs may then be charged to the customer. Uber uses this model as delaying the process to allow a cancellation grace period is not feasible — customers want their rides ASAP. When you request and confirm a ride on Uber, you are allowed to cancel at any time, but if you do after more than 5 minutes, you are charged a cancellation fee.
Technical exceptions
Sagas are meant to deal with deterministic business processes and their rollback. You can think of Sagas as failure management patterns for business processes. They are not very good at dealing with technical exceptions, which are indeterministic by nature.
If we attempt to cancel a Saga when encountering a technical error on one of the steps, it’s very likely that the compensatory action to reverse it will also experience the same error, leading the Saga to be stuck in a loop.
Earlier in this post, I have already touched on how to deal with technical errors. Retrying with some sort of exponential back-off within agreed thresholds, and if that still doesn’t resolve the issue, you can resort to escalation and manual intervention if needed.
Dealing with technical errors should ideally not be part of the Saga. It should instead be done on another technical layer that the Saga runs on top of.
“What you need to do is to build sort of a technical layer that the saga pattern can run on. That layer needs to make sure that changes it receives are eventually completed. This way it provides a reliable basis for the business layer on top of it by hiding the imponderabilities of distribution from the business layer.
The business layer now can assume that changes it sends to the technical layer will be executed reliably. It does not need to care about potential technical errors. But it needs to take care of potential business level errors.
This is where the Saga pattern shines: Handling business level errors in a distributed context on top of a reliable technical layer.”
Uwe Friedrichsen — The Limits of the Saga Pattern
Idempotency
As the previous design consideration pointed out, technical errors should be dealt with through retries. These retries can be repeated several times; hence, it’s paramount that there are no undesired side effects when they are. To achieve this, all participating services must ensure the part they play in carrying out the Saga is idempotent.
Some transactions are naturally idempotent. For others, you’d need to deduplicate by using a unique ID utilising patterns such as the Inbox pattern, which all boils down to saving the unique ID for every processed message in a datastore and inspecting this store whenever a new message arrives to determine whether it has already been processed.
This outbox can be implemented as a standalone or integrated into processing. You can integrate by keeping and checking that ID within your business logic. There are multiple ways this can be achieved. You can, for example, use a unique ID from the messages as your aggregate ID and check the aggregate state to determine if the action triggered by this message has already been performed on the aggregate and, if so, do nothing. If you can’t use any of the unique IDs from the message as your aggregate ID, you can use a persisted document/table to map message IDs to aggregate IDs.
When it’s standalone, you can either save the message to the Inbox table as part of processing and only acknowledge once all processing is done or save it to the inbox table and acknowledge the message immediately, then use a poller to process the messages; which solution is better depends on your needs.
Managing Lack of Isolation
As described in previous posts in this series, Sagas are a way to implement transactions in distributed systems. However, as opposed to regular transactions, Sagas lack isolation support. They don’t implement the “I” in ACID.
Isolation guarantees that a transaction accesses data as if it has exclusive read/writes to it, even when other transactions occur simultaneously. In other words, it guarantees that after running transactions against a piece of data, the state of the data is the same whether the transactions were run concurrently or sequentially.
Sagas do not provide isolation because each microtransaction/step in a Saga is run independently. Each participating service will run its part of the overall Saga and persist it before the next participating service is run.
Hence, other Sagas could read that data change and use it to make business decisions, oblivious to the fact that these changes are not yet committed and may be rolled back, potentially raising several undesired side effects if not properly addressed. These are called anomalies, and these are:
- Lost updates
- Dirty reads
- Fuzzy reads
To read about this in more detail, including how to mitigate them, I suggest you refer to the Microservices Pattern book by Chris Richardson.