Sagas — Part 4: Design Considerations
Sagas — Part 1: An Introduction Sagas — Part 2: Sagas in Distributed System Sagas — Part 2b: Sagas in Distributed Systems Continued Sagas…
Sagas — Part 1: An Introduction
Sagas — Part 2: Sagas in Distributed System
Sagas — Part 2b: Sagas in Distributed Systems Continued
Sagas — Part 3: Choreography Instead?
In previous posts in this series, I have introduced Sagas, given an example of a Saga in distributed systems and talked about how they differ from Process Managers.
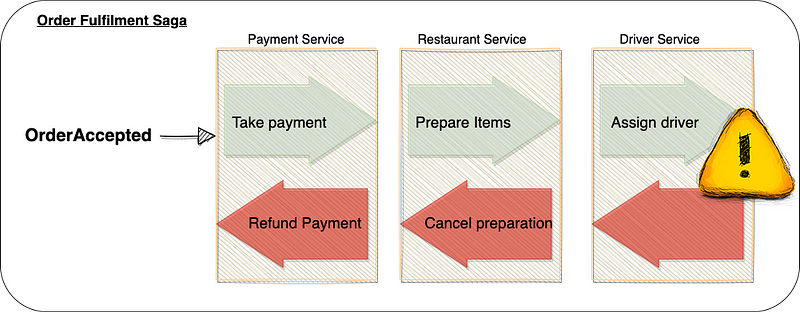
The example Saga given in part 2, shown above, is fairly simple as a process, but there are numerous design decisions and implementation details to ensure it is effective. This is what I’m hoping to cover in this post.
Order of steps
When designing a Saga, it’s prudent to order the steps based on risk. For example, in the above Saga, payment is taken first because:
- it is more likely to fail than the other steps, and
- reverting it by issuing a refund is more expensive.
Restaurants update their menus regularly to remove unavailable items, and there are usually enough drivers to fulfil orders, so they present a smaller risk at this time.
Assigning drivers is also the last step because there are alternative ways to find drivers, as will be discussed in the next section, and therefore it’s less risky than the other two.
However, suppose in the future, there were driver shortages expected to last for some time (think lorry drivers shortage in the UK post Brexit), and the business decided to act as the cost of refunding payments was significantly increasing. In that case, we could change the Saga’s order and start assigning drivers first since it’s more likely to fail. One of the benefits of using Sagas and orchestrators, in general, is the ability to make changes to the modelled process without affecting the participating microservices, hence reducing the risk of change.
Failures
The compensation steps are not just triggered by the first failure. Each step usually has different ways of dealing with failures. These can be both technical and non-technical solutions.
I will discuss dealing with technical exceptions in the next post in this series.
Non-technical strategies are discussed with the business when designing the Saga, as there has to be a consensus on whether they make business sense. Dealing with business failures in every step is done within the microservice responsible for that step and is not exposed to the Saga.
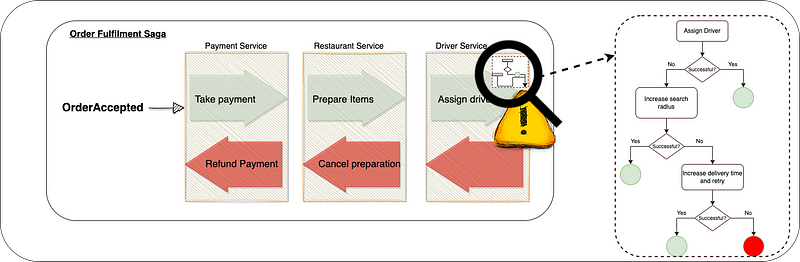
Taking the Deliveroo Saga as an example, failing to assign a driver can be dealt with in a few ways inside the Drivers microservice:
- We could have a strategy to expand the search radius for drivers and compensate them for the longer journeys.
- We could increase the projected delivery time - within pre-agreed limits - and keep trying to find a driver.
Overlapping Sagas
Overlapping Sagas can cause numerous issues when operating on the same underlying data due to the lack of isolation in Sagas — I will discuss this in my next post. Hence, it would make sense to attempt to minimise these scenarios when possible.
You need to step back and map processes in the area you’re trying to model using techniques such as EventStorming and look for processes that are likely to co-occur whilst operating on the same data.
I have seen numerous examples highlighting issues raised due to overlapping sagas, and almost all of them use creation and cancellation sagas running simultaneously, so it makes sense to use these as an example. There are a few ways to avoid overlapping Sagas:
Combine them
Look for ways to combine overlapping Sagas. For example, instead of having one saga for the creation and another one for cancellation, try to model the process in a way that cancellation is simply just reversing the completed steps of the creation Saga and then combining them.
Make them sequential
Ensure that one Saga cannot be started until the other one is completed. Looking at the Order Fulfilment Saga in the diagram at the top of this post, the “OrderAccepted” event is coming from a, let’s say, Orders microservice, and it triggers the Saga. The overall order itself is managed by that microservice, and when the Saga is completed, that microservice is informed and can update its internal status to “Completed”. The orders microservice is the technical authority for orders, and so if we want to cancel the order, that is the microservice we call into. The Orders microservice can check its internal order status and only start the cancellation Saga if the order status is set to “Completed”, ensuring the two Sagas run sequentially. We can simply reject the cancellation command and instruct the users to try again later if it's not completed.
Eliminate the need for one of them
Utilise “Buyer’s remorse”. I will discuss this further in the next post when talking about cancellations. The general idea is to allow a grace period for cancellations, and once that period has elapsed, you can no longer cancel and are therefore left with only one Saga: the creation Saga — which can only start once the buyer’s remorse period has elapsed.