In the first post in this series, I introduced the current design of the reporting service. And discussed some of the issues with that design. I ended the post with a highlight of the limitations of using message queues to populate this reporting service in particular and aggregation services in general. These were:
- Messages are gone once consumed, and
- Ordering of messages is not guaranteed.
Let’s examine these issues in a bit more depth. Once we get a message off of a queue and process it successfully — in this occasion, storing the information we require from it in a data store — that message is gone. If we want to, let’s say, capture more information from that message because we added an extra column in one of the read models, we can’t. If the data gets corrupted and we want to fix it, we can’t either.
We don’t have access to the data stream used to populate the materialised views. The only way to do this through queues is to ask the services responsible for the required data to resend all the events.
However, republishing events presents a few complications, too, mainly:
- Republishing events sends them to all subscribers
- Republishing must be done every time a new consumer is added
Of course, you can trade off loose coupling and send the events to a particular subscriber. However, this would mean every service has to be aware of all aggregations it is participating in — in this case, reporting. Still, there could be more like a search service, a recommendation service, etc.
Side note: This can be improved by making the process of republishing events to a particular subscriber reusable and automated to reduce coupling and maintenance. One way of doing this is to create a reusable library that can be added to and configured by any service to listen to specific republishing trigger messages containing the destination queue. The library can then read the event streams and (re)send the messages to that destination queue.
To resolve the issues above, we need the event stream to remain available as long as we need it. There are various ways to do this, including:
- Storing the event stream locally, or
- Caching the event stream more efficiently.
Storing event streams locally would solve the issue of spikes in performance on participating services when the aggregator service needs to rebuild its read models. The ripple effect is contained within the aggregator service, and all other services remain unaffected.
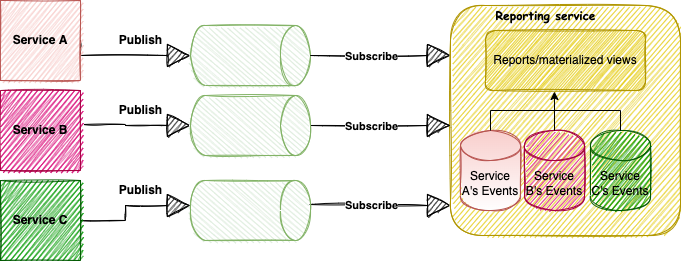
The downside of this approach is that the reporting service must now maintain streams of all participating services. There is a bit of overhead in maintaining those streams in terms of storage and backup. Also, this still does not resolve the extra effort needed to onboard a new aggregator, nor does it guarantee ordering. So how can this be improved?
That brings us to option 2: Caching the event stream more efficiently and this is going to be the topic of my next post in this series.
Originally published at https://medium.com/@ash-mageed on July 14, 2022.